Dotychczas używana baza sz3 jest autorską bazą plikową. Dane są w niej zapisywane z kwantem 10-minutowym i podzielone są na pliki z rozszerzeniem .szb. Pliki te są wielkości miesiąca, a wewnątrz zawierają uszeregowane ciągiem dane w postaci znacznika czasowego i następującej po nim wartości.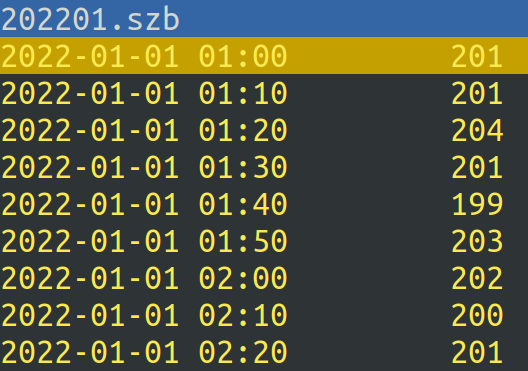
Rys.1 Podgląd struktury pliku .szb z konsoli narzędzia szbedit
To jakie dane przynależą do jakiego parametru definiuje struktura katalogów, w którym dane zostały umieszczone. Cały system odczytywania tychże danych jest skrojony pod powyższą architekturę - implikuje to pewne trudności jak brak możliwości przechowywania większych danych (do których zapisu potrzeba więcej niż 16-bitów), brak możliwości rozbudowania systemu o archiwizację pomiarów z większą rozdzielczością czasową oraz skomplikowaną edycję danych za pomocą dedykowanych narzędzi. Danych nie da się także łatwo odczytać bezpośrednio bez wiedzy w jakim formacie zostały zapisane.
Pod maską naszego nowego backendu sz5 kryje się baza danych InfluxDB. Jest to baza stworzona od podstaw specjalnie na potrzeby przechowywania danych czasu rzeczywistego. W dodatku najszybsza w swojej klasie (porównanie można zobaczyć samemu pod tym adresem). Napisana w języku stworzonym przez Google - Golang, gwarantuje szybkość, niezawodność, elastyczność oraz skalowalność. To dojrzały produkt, w który zainwestowano do tej pory ponad 120 milionów dolarów. Za rekomendację może posłużyć fakt, że Influxa używają takie firmy jak
Rys.2 Firmy korzystające z InfluxDB
InfluxDB podobnie jak sz3 dane indeksuje za pomocą znaczników czasowych i przechowuje je w tzw. shardach o wielkości zdefiniowanej przez użytkownika - można tę wielkość skonfigurować tak, aby najlepiej pasowała do konkretnego zastosowania, co optymalizuje wydajność bazy danych w szczególności, gdy zawiera już dużą ilość danych. Dane, które są potrzebne w bieżącej chwili przechowywane są pamięci RAM - to dodatkowo przyspiesza działanie bazy, ponieważ dostęp do pamięci RAM jest wielokrotnie szybszy od odczytu z dysków HDD/SSD. Baza sz5 dzięki temu, że korzysta z Influxa może przechowywać dodatkowe informacje o pomiarze – nie tylko samą wartość liczbową, ale też informacje w postaci ciągu znaków jak na przykład rodzaj próbki – domyślnie sz5 zapisuje dane z rozdzielczością 10 sekund.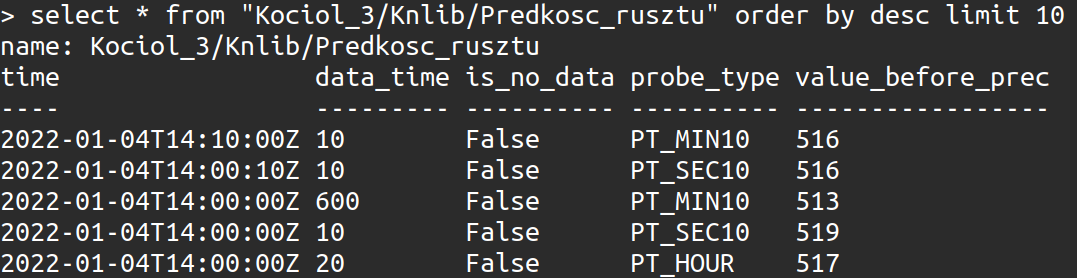
Rys.3 Odczyt danych z bazy sz5 za pomocą zapytania SQL
W związku z tym, że Influx kompresuje shardy i dane są przechowywane w spakowanych archiwach można również bardzo szybko zrobić backup całej bazy, a w razie awarii taki backup bardzo szybko przywrócić - czas przywrócenia kilku lat danych z ciepłowni to dosłownie kilka minut!
Dla ułatwienia pracy z danymi InfluxDB udostępnia interfejs do złudzenia przypominający SQL znany z wielu innych relacyjnych baz danych, więc edycja bazy to bułka z masłem dla kogoś kto miał już wcześniej styczność z innymi bazami danych.
InfluxDB jest w stanie przyjmować ogromne ilości danych jak również pracować pod wysokim obciążeniem obsługując dużą liczbę zapytań na raz. Wierzymy, że w połączeniu z SZARPem przyczyni się do wydajniejszej pracy wielu polskich ciepłowni.